A munkám során egyre gyakrabban kerülök kapcsolatba az Azure-rel. Hogy ez véletlen-e vagy annak a jele, hogy egyre több helyen oldják meg felhőben a felmerülő problémákat, az persze kérdéses. Mindenesetre az biztos, hogy sok esetben és sok projekt/cég szempontjából ez az egyszerűbb módja a megoldásnak, hiszen rengeteg új eszközt ad a kezünkbe, és sokszor olcsóbb is, mint a saját infrastruktúra kiépítése és üzemeltetése. Persze tudom, biztonság, stabilitás és egyéb ellenérvek szoktak elhangozni vele szemben, de ugye mindenkinek megvannak a preferenciái.
Aki viszont belevág, az tényleg egy komplex és nagyon sokrétűen használható eszköztárhoz jut. Ennek az eszköztárnak egy nagyon hasznos eleme az Azure Data Factory (ADF), amit a most következő blogposztomban szeretnék bemutatni.
Mi is ez a Data Factory? Egész röviden, egy felhős adatintegrációs szolgáltatás az Azure-ön belül, amelyben előre definiált, vagy saját magunk által összeállított folyamatok segítségével oldhatjuk meg on-premise és felhőalapú rendszereink között az adatok mozgatását és azok átalakítását.
De nézzük meg közelebbről a megoldást, hogy mit érdemes még tudni róla, hogyan működik az egész?
Az ADF lehetőséget nyújt számunkra, hogy úgynevezett pipeline-okat hozzunk létre. Ezek adat vezérelt munkafolyamatok, amelyek az adataink egyik helyről a másikra való mozgatását és adott esetben átalakítását teszik lehetővé ütemezett módon.
Ezek a pipeline-ok tipikusan 3 részfolyamatra oszthatóak:
- Hozzákapcsolódnak a szükséges adatforrásokhoz, ami lehet egy adatbázis, web service vagy egy file, stb. a felhőben, vagy on-premise. Ezután a kiválasztott adatokat a pipeline-on keresztül feltölti egy központi helyre a felhőben további elemzéshez.
- Miután az adatok egyben vannak, lehetőségünk van azokat átalakítani, és dúsítani
- Végül az átalakított adatokat visszavihetjük akár egy on-premise célhelyre (mint egy SQL szerver), vagy a felhőben is tarthatjuk, hogy valamilyen BI vagy egyéb elemző eszközzel feldolgozzuk.
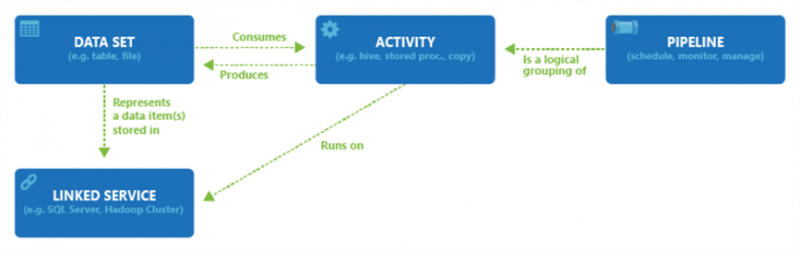
A fenti három részfolyamathoz négy komponens együttműködésére van feltétlenül szükség, hogy meghatározzák mind a bejövő, mind a kimenő adatokat, feldolgozzák azokat, illetve ütemezzék az egész folyamatot, hogy végül a kívánt adatfolyam létrejöjjön és működjön.
- Dataset: ezek jelentik azokat az adatszerkezeteket, amiben az adatainkat tároljuk. Értelemszerűen a bejövő adatszettek a pipeline-ba bejövő adatok, míg a kimenő adatszettek a folyamat eredményeként létrejövő adatok.
- Pipeline: A végrehajtandó folyamatok (activities) csoportja. A kiválasztott folyamatok csoportja együtt hajtja végre azt a feladatot, amit meg szeretnénk oldani.
- Activities: egy-egy folyamat, amely az adatokon végrehajtásra kerül. Ezeket két típusra lehet osztani: az adat mozgatási-, és az adat transzformációs folyamatok csoportjára.
- Linked services (kapcsolt szolgáltatások): azokat az információkat jelentik, amelyek ahhoz kellenek a Data Factory-nek, hogy a külső forrásokhoz tudjanak kapcsolódni. Például: egy Azure Storage connection string, amivel ahhoz csatlakozhatunk.
Ezeken kívül vannak még az úgynevezett triggerek. Ezek képviselik az ütemezési beállításokat a pipeline-okban, és olyan beállításokat tartalmazhatnak, hogy mikor induljanak azok el, vagy álljanak le, milyen gyakorisággal hajtódjanak végre, stb. Csak abban az esetben van rájuk szükség, ha automatizálni szeretnénk a folyamatainkat egy meghatározott ütemezés szerint.
A gyakorlatban valahogy így néz ki a négy komponensük és a közöttük lévő kapcsolat:
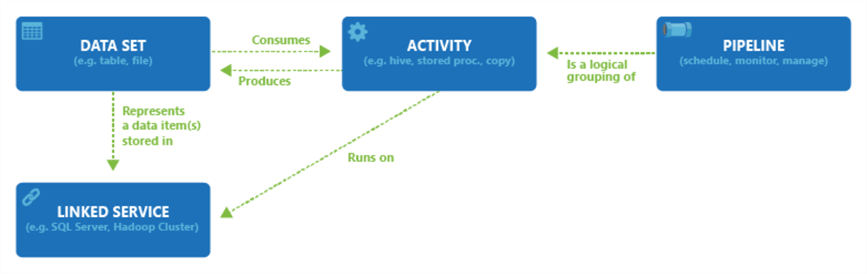
Ahogyan azt a poszt elején már említettem, akár mi magunk is összeállíthatunk teljesen egyedi pipeline-okat, de a leggyakoribb feladatokra külön template-ek is elérhetőek. Ez utóbbi nagyszerű lehetőséget kínál arra, hogy akár különösebb hozzáértés nélkül is megoldjunk olyan feladatokat, amelyek máskülönben komoly fejtörést okoznának.
Egy példát említek: az egyik ügyfélnél egy olyan adatbázisból kellett időszaki elemzést készíteni Power BI-ban, ahol amúgy csak az adatok éppen aktuális állását tárolták. Ehhez az ADF pont kapóra jött, mert a segítségével lehetségessé vált, hogy az Azure-ben létrehozzak egy olyan verziót, ahova minden nap feltöltésre kerültek ezek az adatok egy időbélyegzővel ellátva és így már lehetővé vált az időbeli alakulásukat is vizsgálni.
Tudom, ez megoldható sok más eszközzel is, de itt az a nagy szó, hogy egy-két óra olvasgatás és gondolkodás után úgy tudtam ezt megoldani, hogy előtte semmiféle gyakorlatom nem volt az ügyben…
Pont ez a könnyű kezelhetőség az ADF legnagyobb előnye. Bárki számára elérhető és kipróbálható, ráadásul nem kell semmilyen más eszköz a használatához (bár ha úgy tetszik az Visual Studio-ba is beintegrálható). Amennyiben tennénk vele egy próbát, akkor az Azure-ben a “Create a resource” opció alatt az “Analytics” menüpontban találhatjuk meg a szolgáltatást, a többi pedig már adja magát!